

Audio content—from radio broadcasts and podcasts to community call-ins—drives vital conversations across Africa. For businesses, agencies, and other stakeholders, tracking and analysing this material is critical to understanding public sentiment, identifying emerging market trends, and maintaining brand reputation. However, mainstream speech recognition solutions frequently overlook African languages. Without this key tool to bridge Africa’s rich oral traditions, organisations struggle to capture localised insights from valuable broadcast sources.
As a South African company specialising in African languages, Saigen serves customers across six languages in five Sub-Saharan African countries. Most recently, we introduced Amharic—spoken by over 32 million people and recognised as Ethiopia’s official language. By offering accurate transcription in these local languages, we enable organisations to monitor audio media more effectively and make data-driven decisions that resonate with African audiences.
Challenges in Amharic ASR
Amharic poses unique hurdles for automatic speech recognition. It is an under-resourced language, offering limited transcribed audio data. Beyond data scarcity, Amharic’s rich morphology and Ge’ez script add complexity: the language features numerous word forms that shift with prefixes, suffixes, and internal vowel changes, while the script itself morphs characters based on context. These variations are further complicated by dialect differences across regions. Traditional word-level models often fail when encountering out-of-vocabulary (OOV) words—an issue exacerbated by Amharic’s vast range of possible word forms.
Subword Modeling: Our Approach and Results
To address these challenges, we adopt subword modeling rather than attempting to recognise complete words. By splitting words into smaller segments, the model can piece together new or rare words from known elements, significantly mitigating the OOV problem. In our tests, subword-based recognition notably reduced error rates compared to standard word-level approaches. Balancing the number of subword units has proven critical, ensuring enough detail to capture Amharic’s morphology without overcomplicating the model.
We incorporate this approach into our media monitoring speech recognition training process, leveraging our extensive experience in African language speech recognition. By integrating this technique, we further enhance our technology’s ability to accurately capture rare, domain-specific, and newly emerging terms—an invaluable capability for effective media monitoring.
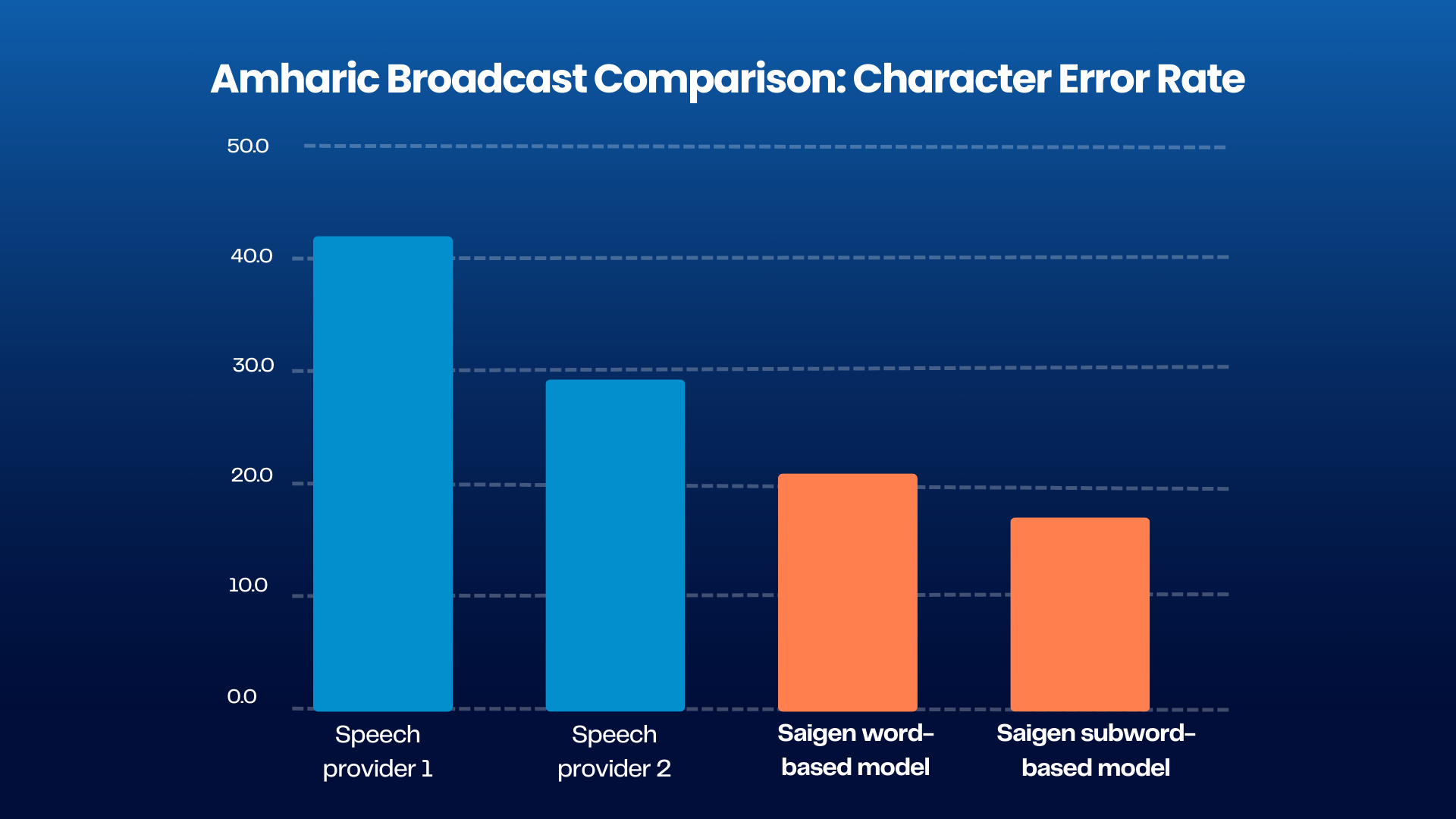
We benchmarked our Amharic system against other providers by collecting two hours of radio broadcasts and had human annotators produce reference transcripts. Our subword-based method achieved notably lower error rates, underscoring the importance of subword modeling for accurate and robust Amharic speech recognition.
Conclusion: Real-World Impact
Accurate Amharic speech recognition offers a clear benefit for media monitoring, allowing organisations to parse hours of audio in a fraction of the time required for manual transcription. Equipped with keyword monitoring capabilities, stakeholders can surface critical events, brand mentions, or trending topics in real time. Whether it's local health authorities verifying public service messages, political analysts tracking election coverage, or content creators refining their programs based on listener feedback, converting raw Amharic audio into actionable insights is essential for truly understanding and engaging with Ethiopian audiences.



{kind=link}
{kind=link}
{kind=link}